太平洋高気圧が北へ押しやった梅雨前線がちょうど日本列島の上にある今日も雨降り.屋外を通って木材を搬入すると濡れてしまうのでシャワールーム作りはお休みです.
てなわけで、雨降りでもやれるのはTensorFlowだけであります.
「TensorFlow2プログラミング実装ハンドブック」第4章のsource codeを見てゆきます.
でも、クラスの中で何やってるのかがさっぱりわからん......
第4章前半で実装するのはこのニューラルネットです.xを2つの山に分類します.

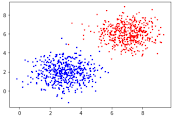
ニューラルネットに投入するものです.
これだけで500個のベクトルを作れるのは便利でいいや.
x1 = np.random.randn(500,2) + np.array([3, 2])教師データも作っています.
t1 = np.array([[0] for i in range(500)])
分布が2つの雲状になっているので、赤と青に分類するのがニューラル君にさせたい仕事です.
In[3]: 上の図のニューラルネットを定義する
MLPはmulti layer perseptronの略かな?
class MLP(tf.keras.Model): Kerasから継承
def __init__(self, hidden_dim, output_dim): 隠れ層2次元、出力層1次元として後で呼び出されることになる
self.l1 = tf.keras.layers.Dense(hidden_dim, activation='sigmoid') 隠れ層L1
self.l2 = tf.keras.layers.Dense(output_dim, activation='sigmoid') 出力層L2
def call(self, x): ニューラルネット本体
h = self.l1(x) 隠れ層L1の計算
y = self.l2(h) 出力層L2の計算
return y 出力層L2を返す
たったこれだけでニューラルネットを定義できちゃうんだから便利でいいわ.
もっと層数が多かったり多次元だったりするニューラルネットを定義したければ、
MLP(10,10,8,6,10,10,3,1)
などと記述すればいいんだろうなぁ.なんかスゲー便利じゃね?
なお、kerasというのは、TensorFlowを便利に使えるラッパーレイヤーです.より一層black boxに....
In[4]: 誤差計算を定義する
bce = tf.keras.losses.BinaryCrossentropy() 出来合いの誤差計算objectを流用
def loss(t, y):
return bce(t, y)
tは赤青の教師フラグで0または1
yはニューラルネット出力で0~100%
BinaryCrossentropy()は内部で何をやっているのか?
sourceを読んだわけじゃないので概ね想像ですが、、、
Binaryというワードの意味するところは、t=0または1、すなわち赤青の2値分類に対応した誤差計算であると名乗っているんじゃないかと思います.
そして、tとyを材料にblack boxがやっている計算は、、、
教師データが10個あるとします.ゆえに正答tは10個です.Xも10個です.
それぞれに対してニューラルネット出力yも10個得られます.yは0~1のfloatです.下表では%で表しています.

tとyが誤差計算関数loss(t,y)に与えられますと返り値は-0.0005979です.(実際は対数で計算してるのかもしれませんが不明です)
この-0.0005979は何者なのかが重要です.
1番目: 正答は1です.ニューラル君は75%だと言ってる.>50%なのでニューラル君も1だと判定しました.おめでとう正解です.得点は75点です.
2番目: 正答は0です.ニューラル君は27%だと言ってる.<50%なのでニューラル君も0だと判定しました.おめでとう正解です.得点は100-23=73点です.
3番目: 正答は0です.ニューラル君は「96%だから絶対1だ」と主張しました.残念ですが大ハズレです.得点はたったの100-96=4点です.
10番目まで計算すると、得点(tとのマッチ度)が10個出てきます.10個の得点を掛け算したものが0.0005979です.さらに符号反転して-0.0005979です.
掛け算ですから、10個とも100点だったらloss()=-1で最高得点です.3番目みたいな「大外し」をしでかすと鬼の様に足を引っ張ってloss()=0に近づいてしまいます.
ニューラルネットは教師あり学習を積み重ねることによって、lossの最小化(-1に近づける)を図ります.
In[5]: ニューラルネット内部に隠れたwとbを1回だけ修正するルーチン
optimizer = tf.keras.optimizers.SGD(learning_rate=0.1) 修正object
def train_step(x, t): 修正ルーチン
with tf.GradientTape() as tape: 内部状態を記録する謎のblack-box
outputs = model(x) ニューラルネットMLPのインスタンス
tmp_loss = loss(t, outputs) 誤差を計算する
grads = tape.gradient( tmp_loss, model.trainable_variables) 自動微分
optimizer.apply_gradients(zip(grads, model.trainable_variables)) 修正
return tmp_loss 誤差を返して終了
W修正のキモはどうやって微分するの?ってことです.微分さえできてしまえば後はお茶の子さいさいですから.とするとGradientTapeが最重要ですがblack-boxでワケワカメ.
TensorFlow tutorialにGradientTapeの解説が少しあります.GradientTapeは内部計算の全てを記憶するそうです.またトップダウン型自動微分が実装されているとのこと.wikiの自動微分へリンクされていて、自動微分は数式微分でも数値微分でもないと書かれています.
自動微分とはなんぞやですが、ひら理解によると、合成関数の微分で順次解いてゆく計算手法で、ボトムアップ型自動微分は以下のような事をやっているみたいよ.
1)W111で偏微分したいとすると、ニューラルネットのW111~yまでを残して他は全部切り捨てる.そうしないと混ざってしまって偏微分にならないと思う.

3)sgd=sgd(u11) をu11で微分する ③
4)u21=w211 sgd をw211で微分する ④
5)y=sdg(u21) をu21で微分する ⑤
6)微分=②③④⑤
個々の微分を実行するには、各変数の⊿が必要です.⑤の場合は⊿yと⊿u21が必要です.それはたぶん、1回過去の修正動作時のyやu21との差分を採用しているのだと思います.⑤=⊿y/⊿u21と計算すれば微分できたことになるんじゃね?
wikiによるとこのような自動微分は1960年代に最初の論文が出ているらしい.便利なことを考えてくれる人がいてよかったですね.
In[6]: いわゆるmain()がここ
model = MLP(2, 1) 隠れ2次元、出力1次元のニューラルネットを生成
for ~ next
tmp_loss = train_step(x_[start:end], t_[start:end]) train_step()はIn[5]で記述した修正ルーチン
他のごちゃごちゃした物は割愛
何をやってるかだいたい想像ついた感じー.
自動微分というものを初めて知りました.
めんどくさいニューラルネット等の記述が簡単ポンで便利でよかよか.
かしこ
>MLPはmulti layer perseptronの略かな?
返信削除個人的には、ここにツボりました。
※なんだかんだ言って、これも単なる
「パーセプトロン」
の、末裔なんですね。
(この「概念」は、古くは、'50~'60年代には、既にあったはず。いわゆる、古くて新しい概念です。この辺
https://ja.wikipedia.org/wiki/%E3%83%91%E3%83%BC%E3%82%BB%E3%83%97%E3%83%88%E3%83%AD%E3%83%B3
が、参考になる。)
その昔は、技術的制約から、ニューロンの数が限られていたため、
「そんなに大した成果」は、得られなくて、一時下火になってたのですが、
昨今の「マシンパワーの増大(スマホでさえ、ギガオーダーのCPU/メモリを積んでいる)」
の、恩恵を受けて、また研究が盛んになってきたようですね。
(いわゆる、「量から質」への、転換でしょうか。)
そういう意味では、現在は、
「ギガ」レベルのリソースで、これだけの成果が出てることを考えると、
これが、
「テラ」レベルになって、それこそ、
「シンギュラリティ」が、起きるのかもしれません・・・(と、夢?がふくらむ)
化石かと思っていたパーセプトロンなのでしたー
削除アタマのいい人が戦後に考えていた理論が誰にでも使えるようになっておめでとうございます!
そもそも「ニューロン」は、脳の「ハードウエア」を、模倣したものなので、
削除実際の脳(脳細胞は、1000億くらいあるといわれている)と、同じ数だけの
「ニューロン」を用意すれば、
「シンギュラリティ」が、起こる可能性は、十分にあるかもしれません。
※1000億 = 100,000,000,000 = 100G 位なので、
「あと、百倍」の、素子があれば出来るかも?
(あるいは、脳は10パーセント位しか使われない説を取れば、10倍くらい?
でも、1ニューロン=1バイトではないと思うので、やはり100から1000倍は、必要なのかな?)
まぁでも、人間だって全員に「知能」があるとは思えないので、これは、
「人工頭脳(ハードウエア的な意味)」には成り得ても、
これが即「人工知能」には、ならないんだろうな・・・
>やはり100から1000倍は、必要
削除やはり、
「テラバイト」
は、最低要るんだろうな。
「キミは何テラバイト?」~♪
鬼のベクトル演算でAIも発熱が大変そうですw
削除水冷式か、水没型か、、、
>「キミは何テラバイト?」~♪
削除なつかっし。かやりんー!